HI, I AMJAVIDAN KARIMLI.
Data Scientist with a strong background in data engineering and focused on applying AI across different domains. I build scalable systems that turn data into meaningful insights.

FEATURED PROJECTS
Here are some of the projects I’ve developed over the years, spanning different data domains from data engineering to machine learning.

Explainable Soccer Match Outcome Prediction
Developed an explainable machine learning framework to predict soccer match outcomes using match statistics and player performance features. Integrated SHAP-based model explanations to surface the most influential factors behind predictions, enabling analysts to interpret results and validate model reasoning. Delivered visual insights alongside prediction confidence to support tactical decision‑making and post‑match review.
PROJECT INFO
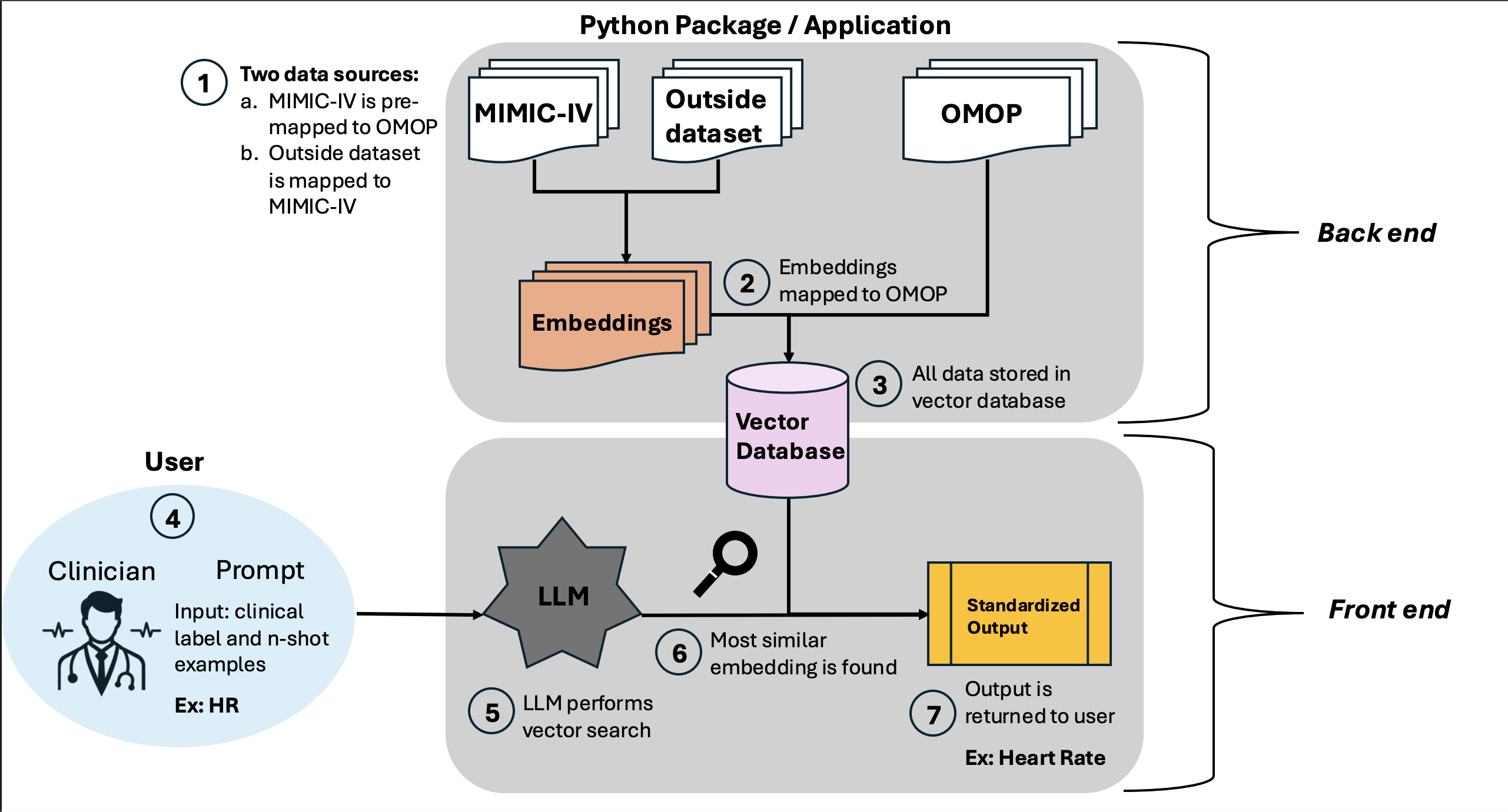
eHRmonize: ICU Clinical Data Harmonization
Developed a harmonization framework to align heterogeneous ICU flowsheet variables across MIMIC-IV and eICU collaborative research datasets. Designed embedding-based methods for semantic matching of clinical measurements, reducing manual alignment overhead. Enabled cross-institutional predictive modeling by producing harmonized variable representations suitable for mortality and length‑of‑stay tasks. Integrated clinician feedback loops to validate mappings and iteratively refine embedding strategies for higher fidelity clinical alignment.
PROJECT INFO
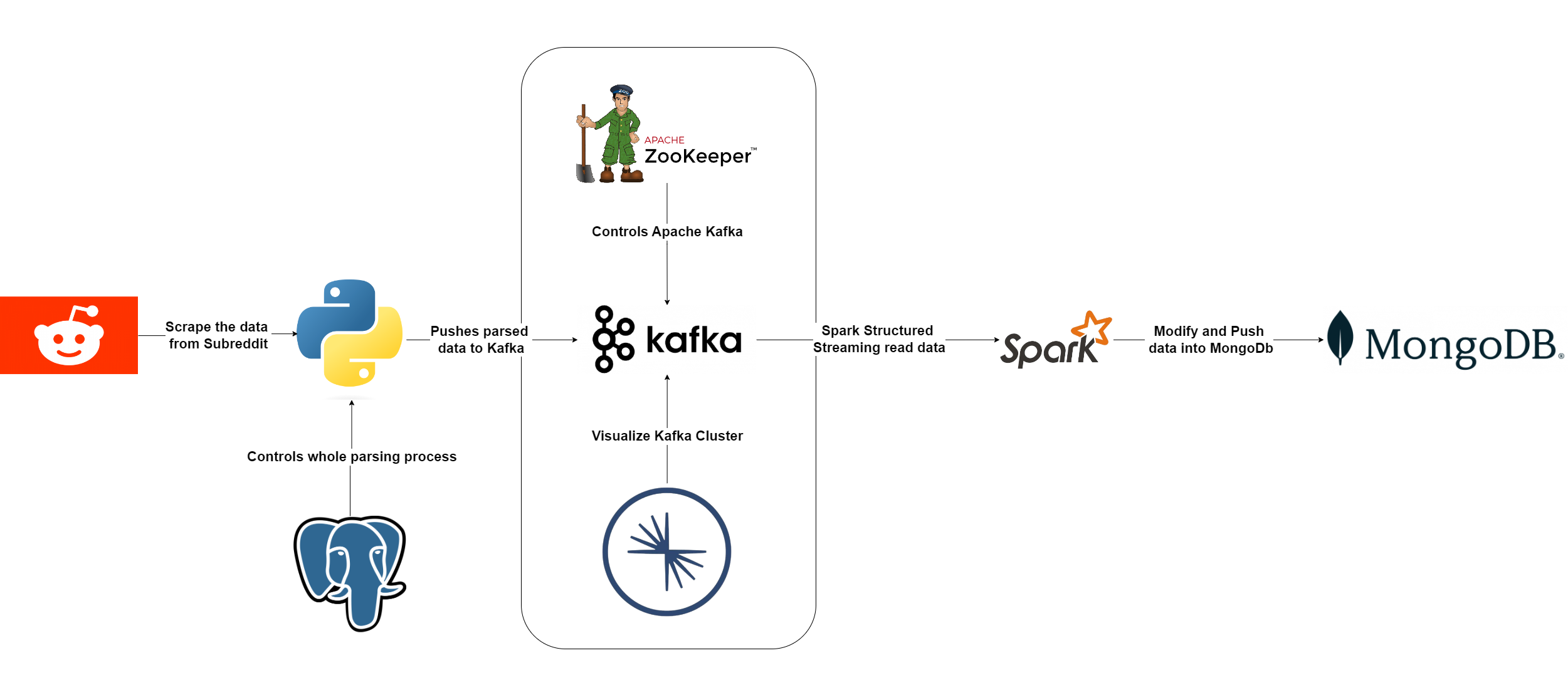
Reddit Asynchronous Streaming Parser
Designed and deployed an end-to-end data pipeline that asynchronously scrapes Reddit subreddits with Playwright, streams events through Kafka, processes them in Apache Spark Structured Streaming, and stores posts and comments in MongoDB with PostgreSQL orchestrating parsing history and control logic. All core infrastructure is containerized with Docker for reproducible, scalable deployment.
PROJECT INFO
MY EXPERIENCE
Data Science Intern
Siemens Healthineers
Jun 2025 – Aug 2025
Developed predictive churn models in Databricks (XGBoost, RF, KNN, NN) achieving AUC > 0.85 and identifying $20M+ in renewal opportunities. Built reusable utilities accelerating modeling workflows by 40% and deployed an interactive Snowflake-based dashboard enabling business teams to explore model outputs.
Data Engineer
Digital Umbrella
May 2022 – Dec 2024
Migrated the organization’s warehouse to PostgreSQL using a medallion architecture, reducing annual infrastructure cost by $950K. Built production-grade data pipelines with Airflow, Docker, and Kubernetes to transfer 100M+ rows daily and support 80+ public dashboards. Collaborated with data scientists to enhance data readiness and improve modeling performance.
Teaching Assistant
Duke University
Jan 2025 – Dec 2025
Supporting graduate-level courses in Data Engineering and Data Visualization. Assist students with Airflow, Spark, SQL, Docker, CI/CD workflows, and dashboard design. Provide guidance on debugging, reproducibility, and best practices for building scalable and reliable data systems.